

炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会!
来源 | 南风窗
作者 | 荣智慧

唯物的中国芯片产业深度观察
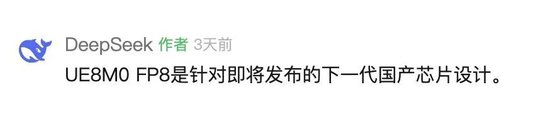
8月21日,深度求索(DeepSeek)公司在官方微信公众号发文,发布DeepSeek-V3.1模型。官方账号在置顶评论表示:“UE8M0 FP8是针对即将发布的下一代国产芯片设计。”
先甭管“UE8M0 FP8”是什么,“下一代国产芯片”这句话,直接把8月22日的上证综合指数送上3800点,创下2015年8月20日以来新高。科创板芯片全数上涨,芯片指数上升10.05%。海光信息、寒武纪两家市值超千亿的芯片巨头双双涨停。
今天(8月25日)早盘,A股三大指数集体高开,沪指续创十年新高。
8月22日,美媒引述消息人士报道,“后门事件”爆发后,英伟达已经告知一些零部件供应商暂停生产“中国特供”H20芯片。
同一天,半导体领域的不断突破为中国股市带来了久违的信心,国产人工智能软件和硬件正加速形成“闭环”,走在局部突破加国产替代的高速路上。
这一切,又要说回到DeepSeek和“UE8M0 FP8”的“算法换算力”上。

股市大涨
股市苦低迷久矣。历经10年,上证指数由芯片企业领跑,终于涨至2015年8月中旬的最高水平。
2015年8月,央行下调人民币汇率,引发金融波动。2017年后特朗普抛出“贸易战”,新冠疫情持续三年,曾经突破5000点的上证综合指数,一度跌至2500点以下,此后也一直明显落后于欧美和日本股市。
中国新兴科技企业深度求索崛起,两番搅动股市。
今年1月,堪与Open AI最新模型媲美的DeepSeek-R1发布,引发英伟达、博通、微软以及光刻机制造商阿斯麦的股价全线下跌,刺激中国科技公司中芯国际、小米、比亚迪、腾讯、阿里巴巴、网易和京东股价持续上涨。
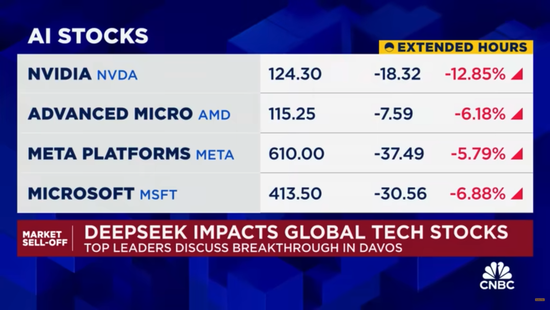
1月28日,受DeepSeek-R1发布影响,美国科技股暴跌
8月22日,深度求索宣布更新的V3.1模型具有“针对下一代国产芯片”的优化方式,极大利好中国算力芯片企业,股市随之出现芯片股领涨、科技股普涨的局面。
与10年前市值(综合A股、港股和美股)排名前十的中国企业相比,互联网公司和电动汽车公司存在感大增,腾讯、阿里巴巴和比亚迪均榜上有名,中国台湾的台积电更是凭借先进制程制造技术盘踞榜首。
新兴产业的壮大,离不开国家战略的指引。在2015年至2023年中国上市企业中,高性能机床、机器人领域和半导体领域的企业,收到的国家补贴占营业收入的比例超过2%。
深度求索两度引爆中国股市,不仅意味着经济发展动力的隐形转移,更折射出中国企业“戮力同心”的团结自主意志。

Deepseek
也就是说,在先进的科技领域,特别是半导体及人工智能领域,中国的创业企业正起到“领头羊”的作用,其他供应链公司和科技企业百花齐放,用先进生产力带动中国经济发展。
同时,有着大模型世界领先地位的深度求索,不以押注英伟达“地表最强”GPU为目标,反而以“算法换算力”,回身等待正发力奔跑的国产算力芯片商,体现的是高远的眼光和理智的情怀。

算法换算力
引发芯片股狂欢的“UE8M0 FP8”,到底是什么?
“UE8M0 FP8”是一种计算机存储和处理数据的数字格式,核心作用是用更少的存储空间和计算资源,高效处理AI模型训练或推理这类对数据精度有要求但又不用特别精确的任务。
它的作用是压缩数据。FP8指的是8位浮点数,这是它的核心技术类型。简单而言,就是用8个“0”或“1”来表示一个数字,比传统的16位、32位格式节省“空间”。
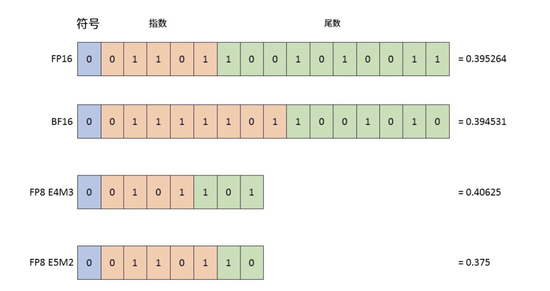
8位浮点数比传统的16位、32位格式节省“空间”
UE8M0是FP8格式下的一个具体的细分规格,重点解决“表示范围”和“精度”的平衡——既不会因为追求节省空间而让数字表示范围太窄(比如装不下太大或太小的数),也可以保证AI计算需要的基础精度,避免算出来的结果偏差太大。
其达到的指数级提升至少包含三个方面,一是算力密度倍增,相同芯片面积下,FP8计算单元数量是FP16的两到三倍。二是功耗砍半,其能耗仅为FP16的四分之一。三是可以装进手机,存储开销降低一半以上,大模型的端侧部署成为可能。
总结来说,“UE8M0 FP8”就是为AI场景设计出来的“高效数据格式”,能让大模型跑得更快,占用的内存/显存更少,还不影响核心性能——属于深度求索的传统艺能,算法换算力。
其实,大部分已经量产的国产算力芯片依然沿用FP16/BF16+INT8的计算通路,尚未集成FP8。
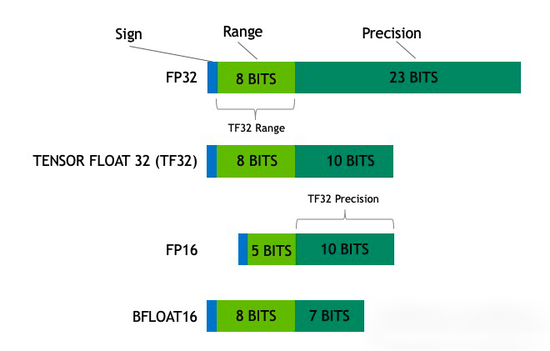
主流浮点精度类型
截至2025年8月,在A股(含已披露招股书、处于上市审核阶段)明确“产品已支持FP8计算精度”的 GPU/AI 芯片公司只有两家:摩尔线程和沐曦,其产品分别对应的是MTT S500和C500系列。
深度求索最新独创的UE8M0格式,主要是与下一代FP8的国产芯片形成了“中国式协同”。而“下一代芯片”有谁,深度求索没有说,暂时只能从中国信通院8月初公布的一批“DeepSeek大模型适配厂商”一窥端倪。
在“首批通过DeepSeek适配测试名单”中,包含中国电信的星辰MaaS平台;华为的推理服务器;寒武纪的AIDC一体机;昆仑芯的P800一体机;海光的DCU加速卡;沐曦的C550一体机及智算集群;中昊芯英的泰则GPTPU人工智能服务器;中科加禾的中科加禾模型推理引擎SigInfer V1.0。
这其中最被看好的是寒武纪,因此市场反应十分直观:8月22日寒武纪涨停,市值超过5000亿,单日猛增866亿美元,取代中芯国际,位居中国半导体行业第一位。当前,寒武纪股价超过1000元,仅次于贵州茅台。
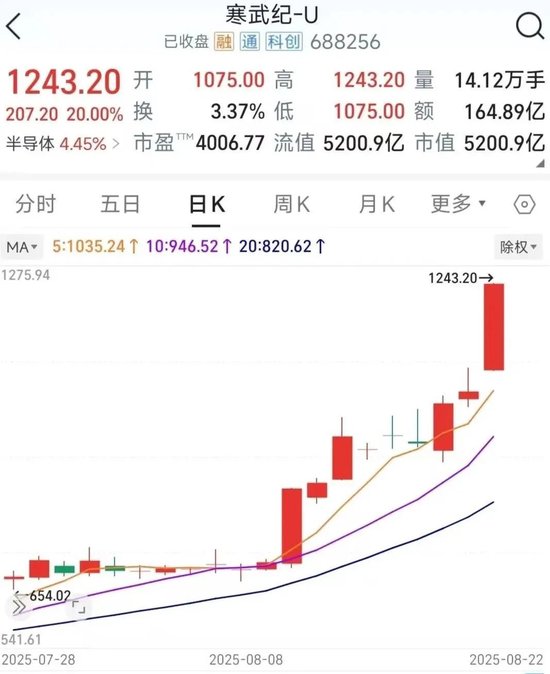
寒武纪涨停

中国式协同
在中国人工智能领域,深度求索的布局正在打造“国产大模型+国产芯片+国产软件系统”的国产化闭环。
不过,闭环只是相对的,中国半导体制造已经摆脱了“简单复制”阶段,但还没到“反向输出”的阶段,达不到TikTok和Shein“定义全球标准”的程度。
从制程上看,7纳米及以下先进制程,EUV光刻机、高阶EDA以及ArFi光刻胶依然存在“卡脖子”的现实,只能通过“DUV加多重曝光”实现有限的量产,性能和良率均落后于台积电2至3代。

EUV光刻机
从设计上看,海思、寒武纪和平头哥的芯片并不比英伟达和高通差,只是在制造环节被锁定在7纳米。
其他领域则都是好消息,比如成熟制程基本自主循环,成熟制程产能大规模扩张,设备和材料小批量试水出海,特别是大基金三期和地方政府基金在本年度预计投资3000亿元,力度也是罕见的。
而且,美国主导的出口管制,无论是“小院高墙”的《芯片法案》,还是屡屡加码的高昂关税,都加速了中国国产供应链自力更生,“被逼出来的创新”正在成为“中国制造”的坚实基础。
因此,回过头来看深度求索的“算法换算力”尤其可贵。即使GPU算力最强的英伟达,一边清H20的库存,一边要卖给中国更高的版本B30A,深度求索依然选择适配算力较低的国产芯片,这不是技术问题,而是意志问题:有了顶流DeepSeek的帮助,中国国产芯片不仅能供给国内需求,更将获得国际话语权。
这也是“中国式协同”的根本意义:一家世界顶级公司还不算,供应链上的公司都要做到世界顶级。想想之前微软和英特尔搞个了“Wintel”也正是同样的道理。

而对于广大网友心急火燎的催促“R2模型怎么还不来”,深度求索官方依然未能给出确切消息。




还没有评论,来说两句吧...